Authors: Razlivina J.S., Serov N.S., Shapovalova O.E., Vinogradov V.V.
Small, 2022, DOI: 10.1002/smll.202105673
Abstract
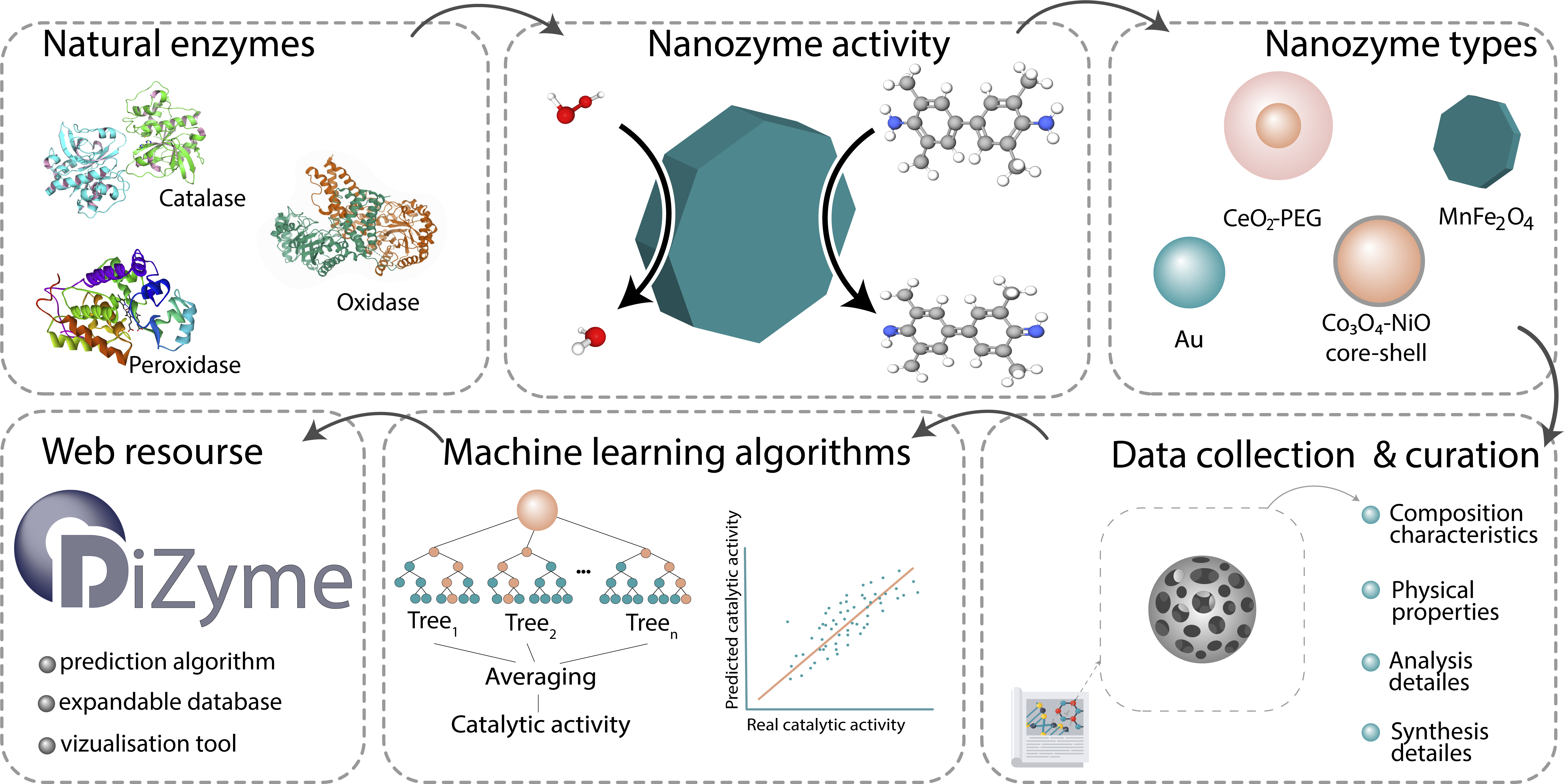
Enzymes suffer from high cost, complex purification, and low stability. Development of low-cost artificial enzymes of comparative or higher effectiveness is desired. Given its complexity, it is desired to presume their activities prior to experiments. While computational approaches demonstrate success in modeling nanozyme activities, they require assumptions about the system to be made. Machine learning (ML) is an alternative approach towards data-driven material property prediction achieving high performance even on multicomponent complex systems. Despite the growing demand for customized nanozymes, there is no open access nanozyme database. Here, a user-friendly expandable database of >300 existing inorganic nanozymes is developed by data collection from >100 articles. Data analysis is performed to reveal the features responsible for catalytic activities of nanozymes, and new descriptors are proposed for its ML-assisted prediction. A random forest regression (RFR) model for evaluation of nanozyme peroxidase activity is developed and optimized by correlation-based feature selection and hyperparameter tuning, achieving performance up to R2 = 0.796 for Kcat and R2 = 0.627 for Km. Experiment-confirmed unknown nanozyme activity prediction is also demonstrated. Moreover, the DiZyme expandable, open-access resource containing the database, predictive algorithm, and visualization tool is developed to boost novel nanozyme discovery worldwide (http://dizyme.net).
Read Full: